PEP8 - Melhores práticas de estilo em Python
Nos últimos tempos, precisei resgatar os códigos de análises que realizei durante o mestrado. Percebi que eles estão um pouco confusos e difíceis de ler. Com intuito de resolver esse problema, decidi buscar entender quais são as melhores práticas de estilo quando programando em Python. Esse post é, então, uma colinha pra que eu possa sempre estar checando caso esqueça de algo. Pretendo ir atualizando essa página frequentemente na medida em que eu avançar na minha pesquisa. Usei como referência o PEP 8 do site oficial python.org. As PEPs, Python Enhancement Proposals, são documentos criados para informar os usuários de Python acerca de padrões, novos atributos, seus processos ou seus ambientes [1]. Especificamente, a PEP 8 indica os padrões de estilo para quem programa nessa linguagem, a fim de que o código possa ser de mais fácil leitura [2]. Então, vamos lá!
(O código aqui mostrado foi copiado da referência [2])
Lista de Conteúdos
Layout do código
Indentação
Padrão: 4 espaços por nível de indentação
Algumas maneiras corretas de utilizar:
# Alinhamento com o delimitador inicial "(".
foo = long_function_name(var_one, var_two,
var_three, var_four)
# Adição de 4 espaços (um nível adicional de indentação) para distinguir a função de seus argumentos.
def long_function_name(
var_one, var_two, var_three,
var_four):
print(var_one)
# A indentação flutuante deve sempre adicionar um nível.
# No exemplo abaixo, não há um nível anterior, porém, ainda assim adicionamos um nível.
foo = long_function_name(
var_one, var_two,
var_three, var_four
)
Porém, em algumas ocasiões, é necessário escolher qual das opções é mais adequada para situação:
# Errado. Não é possível distinguir os argumentos e o conteúdo da função.
def long_function_name(
var_one, var_two, var_three,
var_four):
print(var_one)
# Correto.
def long_function_name(var_one, var_two,
var_three, var_four):
print(var_one)
Indentação: estrutura condicional if
Quando um condicional if é muito longo, pode ser que haja um problema ao quebrá-lo em múltiplas linhas:
if (this_is_one_thing and
that_is_another_thing):
do_something()
Não conseguimos distinguir o condicional e seu conteúdo justamente porque a parte if ( contém quatro caracteres. Duas possíveis opções são:
# Adicione um comentário entre as linhas.
if (this_is_one_thing and
that_is_another_thing):
# Since both conditions are true, we can frobnicate.
do_something()
# Adicione uma indentação na próxima linha do condicional.
if (this_is_one_thing
and that_is_another_thing):
do_something()
Indentação: colchete/parênteses/chaves
Além disso, o colchete/parênteses/chaves que fecha uma construção em multi-linha pode se alinhar com o primeiro caractere (não-espaço) da última linha da lista
my_list = [
1, 2, 3,
4, 5, 6,
]
result = some_function_that_takes_arguments(
'a', 'b', 'c',
'd', 'e', 'f',
)
ou alinhar com o primeiro caractere da linha que inicia a lista:
my_list = [
1, 2, 3,
4, 5, 6,
]
result = some_function_that_takes_arguments(
'a', 'b', 'c',
'd', 'e', 'f',
)
Espaço ou tab?
Padrão: espaços são preferíveis a tabs.
No caso em que a indentação de algum código já está em tab, pode se usar tab para casar os padrões. Porém, começando um projeto do zero, é usar espaços (quatro)!
Tamanho máximo da linha
Padrão: limite de 79 caracteres por linha (no geral). Para docstrings e comentários, o tamanho máximo deve ser limitado a 72 caracteres.
Achei meio estranho limitar o tamanho da linha em 79 caracteres, mas o PEP 8 menciona dois motivos pelos quais essa escolha pode ser interessante (além da padronização):
- Esse tamanho permite abrir dois códigos lado a lado, o que ajuda em revisões, por exemplo;
- Certos editores tem um tamanho de linha máxima de 80 caracteres. Tamanhos maiores do que esse “estragariam” a formatação do código, tornando-o de difícil leitura. Assim, o limite de 79 caracteres é um limite seguro (por um caractere).
Porém, para uma equipe que prefere linhas mais longas e possui um código que é exclusivamente/primariamente mantido por ela, se chegarem a um consenso, não há problema em aumentar o tamanho da linha para até 99 caracteres.
Para auxiliar na padronização, o Jupyter Noteboook Extensions conta com uma ferramenta chamada ruler para mostrar uma linha vertical no limite imposto pelo próprio usuário. Abaixo uma figura de um pedaço do meu código mostrando essa ferramenta.
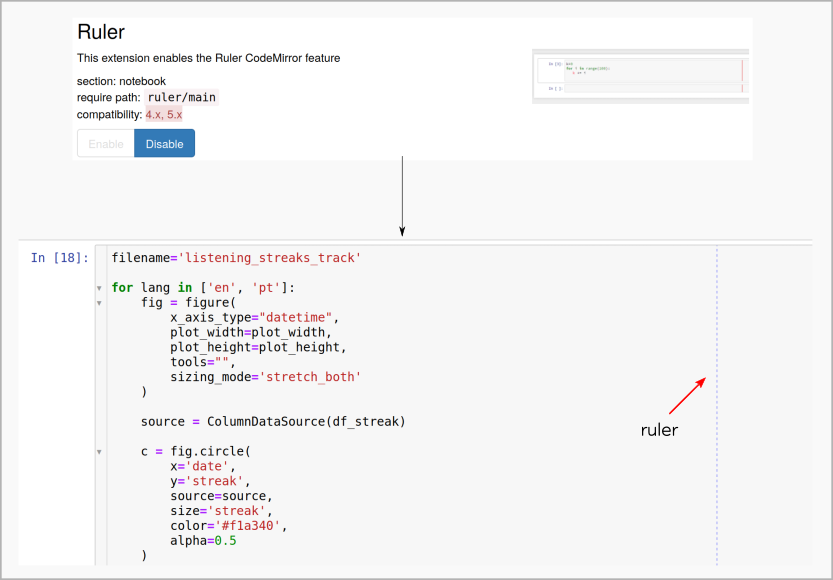
Para quebrar linhas, recomenda-se encapsular a expressão dentro de parênteses, chaves ou colchetes. Quando isso não é aplicável, é possível também usar a barra invertida para quebrar linhas, mas esse é o menos preferível. Por exemplo, quando se declara with ou assert, não é possível usar a continuação implícita:
with open('/path/to/some/file/you/want/to/read') as file_1, \
open('/path/to/some/file/being/written', 'w') as file_2:
file_2.write(file_1.read())
Operadores binários e quebra de linha
Padrão: escrever os operadores no início de uma nova linha.
income = (gross_wages
+ taxable_interest
+ (dividends - qualified_dividends)
- ira_deduction
- student_loan_interest)
É possível melhor entender a relação entre as variáveis descritas. No caso mostrado acima, percebe-se que existem quantidades que devem ser somadas, pois indicam um crédito, e outras subtraídas uma vez que indicam um débito. A posição do operador no início é conveniente, pois a operação sendo realizada é explícita, além do que todos os operadores ficam alinhados, o que melhora a legibilidade do código.
Linhas brancas
Padrões:
-
O início das definições de funções e classes devem começar com duas linhas brancas;
-
Definições de métodos dentro de classes devem ser envoltos de uma linha branca;
-
Linhas brancas podem ser usadas para separar grupos de funções correlatas;
-
Linhas brancas podem ser usadas em funções para separar seções lógicas;
-
Python aceita o comando Ctrl+L para introduzir um espaço em branco, apesar de outras ferramentas usam esses caracteres como separadores de página.
Source File Encoding
Uma pequena e resumida explicação sobre codificação de caracteres:
Cada caractere é armazenado em computadores como uma string de bits – zeros e uns – ou um conjunto dessas strings. Cada sequência de 8 bits compõe 1 byte. Os sistemas de decodificação transformam a informação em bits para linguagem humana escrita.
O ASCII (American Standard Code for Information Interchange) é um sistema de codificação para todos os caracteres presentes na lingua inglesa. Nele, cada caractere é representado por um único byte. Dessa forma, apenas 128 bytes são necessários para representar todos os caracteres e símbolos contidos na língua inglesa.
O padrão UTF-8 (8-bit Unicode Transformation Format), por sua vez, engloba caracteres de outras línguas e até emojis. Esse feito não é possível no padrão ASCII, pois os caracteres têm um tamanho fixo de um byte. Dessa forma, existe um limite de $2^{8} = 256$ possíveis caracteres únicos em ASCII.
No UTF-8, qualquer caractere Unicode pode ser traduzido para uma sequência de números binários e vice-versa. É dessa forma que surge o nome “formato de transformação unicode”, isto é, Unicode Transformation Format. Cada unidade de código é composto por 8 bits (1 byte) e, assim, temos o 8-bit Unicode Transformation Format.
Diferentemente do ASCII, até quatro unidades de código (4 bytes) podem ser utilizadas para representar um caractere, isto é, sua forma decodificada. Até quatro unidades porque a quantidade é dinâmica, “poupando” espaço quando possível. Por outro lado, a forma codificada (o que chamamos de code point) é totalmente definida em termos do padrão de codificação Unicode especificado. O code point é um valor inteiro, especificado de acordo com uma representação hexadecimal. Assim, existem 1,114,112 code points (de $0$ a $10FFFF$ ou $17\cdot16^{4}$) divididos em até 17 planos, que correspondem ao prefixo de $0$ a $10$ em notação hexadecimal.
Por exemplo, o caractere “A” é representado pelo code point U+0041 (U+número hexadecimal do code point) e tem a representação binária 01000001 (1 byte). Enquanto isso, o caractere “あ” do alfabeto japonês hiragana – que também se lê “a” – é representado pelo code point U+3042 e tem representação binária de três bytes: 11100011, 10000001 e 10000010.
Os primeiros 256 caracteres da biblioteca Unicode são aqueles presentes no ASCII, estes representados apenas por um byte. Portanto, a biblioteca ASCII é um sub-conjunto do UTF-8 e textos em ASCII têm compatibilidade com textos em UTF-8.
Padrões:
-
O código no core da distribuição Python deve sempre usar UTF-8 (ou ASCII na versão Python 2);
-
Arquivos usando ASCII (em Python 2) ou UTF-8 (em Python 3) não devem ter uma declaração de encoding;
-
Nas bibliotecas padrões, encodings não-padrões devem ser usadas apenas com propósito de teste, ou quando um comentário/docstring precisa mencionar um nome de autor que contém caracteres não-ASCII; caso contrário, preferencialmente inclui-se dados não-ASCII por meio dos escapes \x, \u, \U ou \N;
-
Para versões de Python acima da 3.0, os identificadores (nome dado a classes, funcões, variáveis etc) devem conter apenas caracteres ASCII e usar palavras em inglês sempre que possível (em vários casos, abreviações e termos técnicos são usados e não são em inglês). Além disso, strings e comentários também devem estar em ASCII. As exceções são as seguintes: (a) em caso de teste de features não-ASCII; (b) nome de autores. Autores cujos nomes não são baseados no alfabeto latino (set de caracteres latin-1, ISO/IEC 8859-1) devem fornecer uma transliteração dos nomes em ASCII;
-
Projetos open source com público global são encorajados a adotar políticas similares.
Imports
Padrões
- Os imports de bibliotecas devem estar em linhas separadas:
# Correto.
import os
import sys
# Errado.
import os, sys
Porém, pode-se fazer:
from subprocess import Popen, PIPE
- Os imports devem ser colocados sempre no topo do arquivo, logo depois de qualquer comentário do módulo ou docstrings, e antes de variáveis globais ou constantes do módulo.
Em geral, devem ser agrupados na seguinte ordem:
- Imports da biblioteca padrão;
- Imports de programas de terceiros;
- Imports de aplicações locais/bibliotecas específicas.
Deve haver uma linha branca separando cada grupo.
- Imports absolutos – especificando o caminho inteiro até o pacote – são recomendados, porque eles geralmente são mais legíveis e tendem a se comportar melhor (ou ao menos dar mensagens de erro melhores) se o sistema de importação estiver configurado incorretamente (como quando um diretório dente do pacote acaba no sys.path):
import mypkg.sibling
from mypkg import sibling
from mypkg.sibling import example
Porém, imports relativos explícitos – especificando o caminho relativo da posição atual até o pacote – são uma alternativa aceitável a imports absolutos, especialmente quando se lida com layouts complexos de pacotes quando o uso de imports absolutos seria desnecessariamente prolixo:
from . import sibling
from .sibling import example
Código de bibliotecas padrões deve sempre evitar layouts complexos de pacotes e sempre usar imports absolutos.
Imports relativos implícitos nunca devem ser utilizados e foram removidos do Python 3.
Referências
[1] PEP 1 – PEP Purpose and Guidelines.
[2] PEP 8 – Style Guide for Python Code.
What is UTF-8 Encoding? A Guide for Non-Programmers
What’s the difference between a character, a code point, a glyph and a grapheme?